xv6 系统简单源码分析
xv6 是一个教学操作系统,它是由 MIT 的 6.S081 课程开发的教学操作系统。xv6基于早期的Unix操作系统(Version 6 Unix)的设计思想,并在其基础上进行了简化和修改。xv6 的设计简单且易于理解,代码量相对较小,只有一万多行。初学者可以更容易地阅读和理解整个操作系统的实现细节。xv6 保留了 Unix V6 的许多关键特性和接口,可以在现代硬件上实践 Unix 操作系统的基本概念。
通过 xv6 可以深入了解操作系统的各个方面,包括进程管理、内存管理、文件系统和设备驱动程序等。6.S081 通过实践修改和扩展XV6的代码,加深对操作系统原理和实现的理解。
进程调度
进程 PCB
lock:一个自旋锁,保护进程的p->state,p->chan,p->killed,p->xstate,p->pid等chan: 如果非零,则该进程在该chan上sleeppagetable:该进程的用户页表trapframe:该进程的 trapframecontext:该进程的进程上下文state:进程当前状态- UNUSED, USED, SLEEPING, RUNNABLE, RUNNING, ZOMBIE
1 | // kernel/proc.h |
进程调度
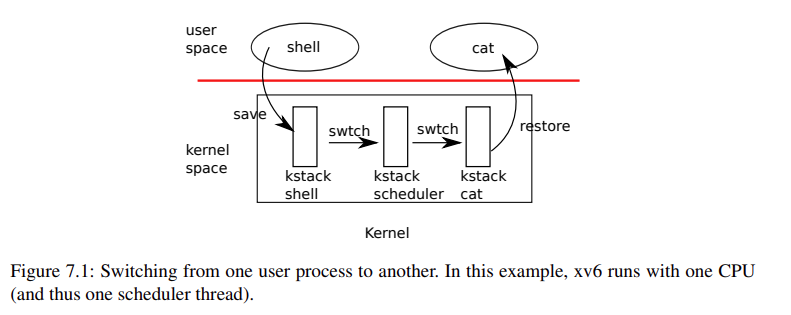
进程调度过程:首先从用户态进程时钟中断转到内核调度进程,再通过内核调度进程找到一个就绪状态的进程,再调度到这个进程。
每一个进程在被创建时(kernel/proc.c中的allocproc()),都会将他的 ra 指向 forkret 这个函数,作为进程最开始的一个运行位置。(scheduler 会通过遍历进程表来找到这个标记为就绪的进程来将程序从 ra 处运行起来)
1 | // kernel/proc.c |
xv6 main 函数初始化完之后进程变为调度进程运行 scheduler() 函数。
1 | // kernel/main.c |
kernel/proc.c 中的 scheduler() 是一个无穷循环,它每次遍历进程表 proc[],对每一个进程尝试加锁,然后如果找到一个进程是就绪状态的,就将其设置为运行状态,然后将当前 CPU 的进程修改为这个进程,然后使用 swtch 切换上下文。调用 swtch 之后会修改 ra 的值,并且 swtch 切换上下文会保留 ra 的值,所以当内核调度进程被切换回来之后,可以回到调用 swtch 的下一句运行。同样的,内核调度进程 swtch 后会转到用户程序的 ra 进行运行,即用户程序上次调用 swtch 的下一句,如果该进程还没有被运行过,那么因为我们在创建进程的时候指定了进程的 ra 为 forkret 这个函数,那么程序首次运行就会进入 forkret 运行。
forkret 函数首先将 scheduler() 里拿到的锁释放掉,然后调用 usertrapret() 回到用户态。(此时因为 fork 进程的时候处于内核态,所以要回到用户态去)。
CPU 会定时发起时钟中断,陷入 Trap,如果一个 Trap 处理函数识别到当前中断是一个时钟中断,那么这个进程将会调用 yield() 函数放弃当前 CPU 的使用权。
yield() 先拿到进程的锁,然后调用 sched() 之后调用 swtch 切换上下文。
这里在 yield() 拿到的锁实际上是在 scheduler() 里面释放的,同样 scheduler() 拿的锁是在 yield() 中释放的。
内存管理
内存布局
物理内存布局
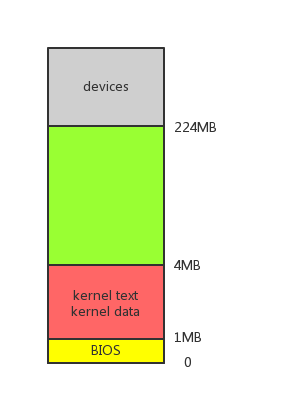
xv6 初始化后物理内存的布局如下图所示。
xv6 内核代码段和数据段被 loader 加载到主存开始的 1MB 到 4MB 空间内。
xv6 BIOS 储存的相关信息储存在主存开始的 0MB 到 1MB 空间内。
xv6 主存开始的 4MB 到 224MB 可以自由分配,映射给内核空间或者用户空间。
xv6 中 devices 区域是其他设备引入的存储空间,仅供设备自身使用,不是主存的一部分。
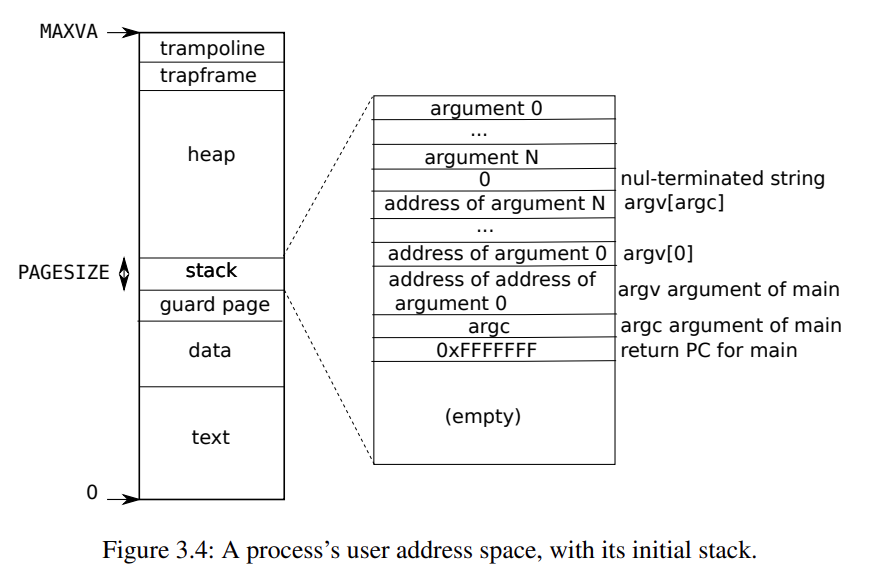
用户地址空间
用户地址空间的顶部是 trampoline 的代码 (用于切换用户态和内核态,只在内核态下被调用*)。
紧接着在 trampoline 的下面是 trapframe 页。
以上两个部分在 kernel/proc.c 中的 proc_pagetable() 进行映射。
1 | // kernel/proc.c |
heap 页用于用户进程调用 malloc() 分配空间。
text 与 data 段存储可执行文件,在 kernel/exec.c 中的 exec() 将指定程序的代码加载进内存,用户地址空间的最底开始。
1 | // kernel/exec.c |
在 data 之上,有两个 page,分别是 stack 和 guard page,guard page 用于防止栈溢出对程序安全造成影响(可能修改了可执行文件的地址),在 kernel/exec.c 中的 exec() 申请这两个 page。
1 | // kernel/exec.c |
stack 中从高地址向地址值生长,参数排列顺序如图所示。xv6 在 kernel/exec.c 中的 exec() 进行栈的填充。(包括参数、返回值)。
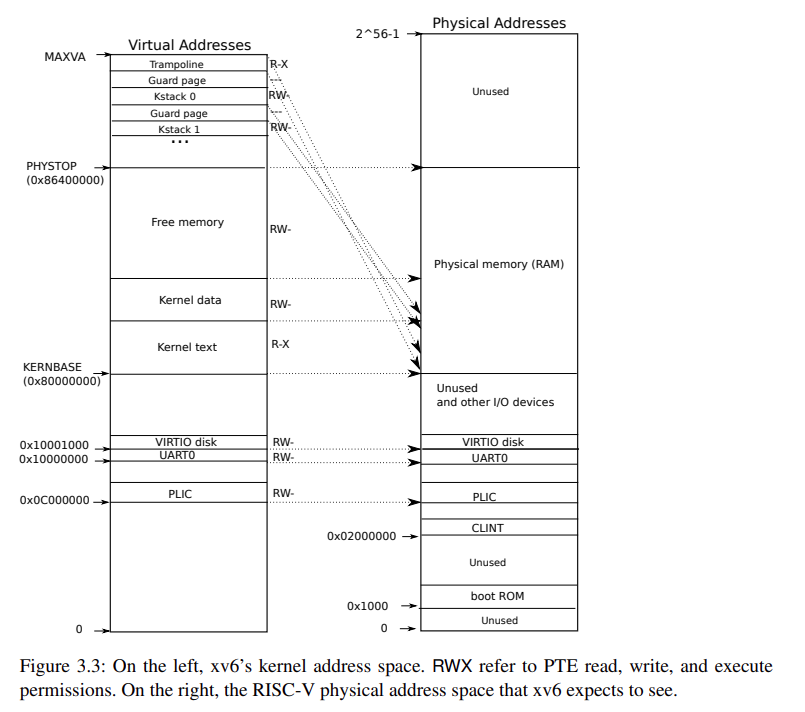
内核地址空间
整个 xv6 默认整个系统只有一个 kernel page。
QEMU 的计算机包含的 RAM 从地址 KERNBASE=0x80000000 到 PHYSTOP=0x86400000。内核起点位置即为 KERNBASE=0x80000000。
内核地址空间与用户地址空间一样,在顶部也同样映射了 trampoline。
trampoline 只在内核态被调用,为什么需要在用户地址空间映射 trampoline 呢*?这里其实因为用户态和内核态并不和页表进行绑定,在 ecall 调用进入内核态之后,寄存器 satp 还没修改(在 trampoline 中修改),所以当前的页表还是用户态的页表,必须要使得两个地址空间都要有 trampoline 的映射,才能 stvec 中存入正确的地址,才能使得其跳入正确的 uservec 地址。
每个进程都在内核页表中分配了一个内核栈 kstack,用于在内核态的栈,在 kernel/proc.c 中的 proc_mapstacks() 进行分配映射。
kernel/kernel.ld 中加载内核,会指定 etext(kernel 程序代码之后的地址)的值。
kernel page 的映射在 kernel/exec.c 中的 kvmmake() 进行直接映射。
1 | // Make a direct-map page table for the kernel. |
内存分配
xv6 将主存(物理内存)中的空闲内存分割成 4KB 大小的页框 (page frame),并用链表将他们组织起来成为空闲链表。
在 kernel/kalloc.c 中进行处理。
空闲内存页表的数据结构:
1 | // kernel/kalloc.c |
先使用 freerange(),将物理内存分割为 4KB 大小的页框:
1 | // kernel/kalloc.c |
分配页,从空闲链表拿链表头出来进行分配:
1 | // kernel/kalloc.c |
释放页,并且将其放入空闲链表的头部
1 | // kernel/kalloc.c |
页表
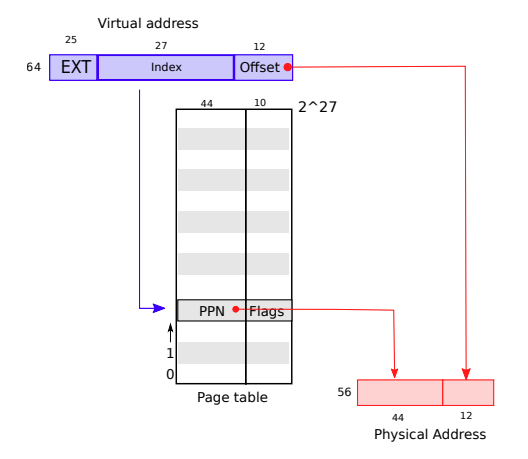
xv6 中只使用低 39 位的虚拟地址 (virtual address,VA)。低 56 位的物理地址 (physical address,PA)。
单级页表
VA 高 27 位用来索引页表(页表有2^27个页表项(page table entry, PTE),每个页表项有一个 44 位的物理页编号(physical page number, PPN) 以及 10 位的 flag 位。
PA 的地址由 44 位 PPN 与 VA 低 12 位的 offset(页内偏移) 组合而成,因此 PA 地址范围为 256
三级页表
VA 高 27 位仍然用来索引页表,但是用前 9 位来索引一级页表,找到对应的 44 位 PPN,末尾补 0 后为二级页表的地址。使用 L1 索引二级页表,以此类推,找到最后的页表项,然后转化为物理地址。
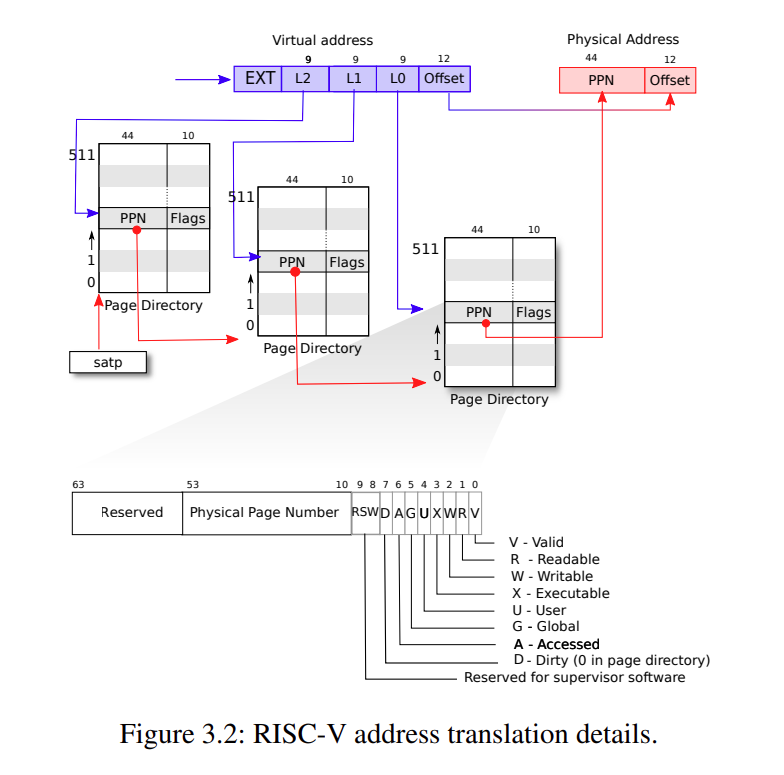
xv6 在 kernel/vm.c 中的 walk() 来通过 VA 找 PA。
1 | // kernel/vm.c |
指令详解
exec
exec() 会将存在文件系统内的程序放入内存并执行。
xv6 在 kernel/exec.c 中的 exec() 实现。
一个 ELF 包含 ELF 头 (struct elfhdr),程序部分头 (struct proghdr),每一个 proghdr 包含需要被加载进内存的程序信息。
然后分配两个页在 ELF 之上,用来当做栈以及 guard page。
然后将程序的参数压入栈中,分配 argc 个位置,然后再分配 argc 个位置,存对应参数的指针,然后将寄存器 a0 放入 argc,寄存器 a1 放入 argv 的指针,initcode.S 将参数放进 exec() 的 a0 和 a1 寄存器,并且将系统调用号放入寄存器 a7。
fork
fork() 将运行着的程序分成两个几乎一样的进程。
xv6 在 kernel/proc.c 中的 fork() 实现。
先分配一个新的进程
1 | // kernel/proc.c |
然后将页表复制,寄存器复制,设置子进程返回值为 0
1 | // kernel/proc.c |
将父进程打开的 fd 进行引用数加一,并且父进程返回子进程的 pid
1 | // kernel/proc.c |
Copy on Write (CoW)
系统调用
trap
system call: 系统调用,用户程序调用ecall发生trapexception: 异常,用户态或者内核态触发异常(如除 0 异常或者页地址错误)interrupt:中断,硬件设备通过信号进行中断,或者时钟中断
trap 都在内核态完成处理
trap 寄存器
stvec: 内核将trap处理函数(uservec或kernelvec)地址放在这里,方便 RISC-V 跳转到处理函数处理trapsepc:trap发生后,RISC-V 将pc保存到这里,在从trap中返回时sret将会把sepc复制回pcscause:trap的类型数sscratch:sstatus: 其中的SIE位控制中断是否开启,SPP位标识trap是从用户态还是内核态来的
用户态发生 Trap
流程:ecall -> uservec (kernel/trampoline.S) -> usertrap (kernel/trap.c) -> usertrapret (kernel/trap.c) -> userret (kernel/trampoline.S)
发生 Trap 时,调用 ecall 后会关闭中断,以防重复中断进入 Trap 处理函数。
然后 xv6 读取 stval 的值并且跳转到其对应的地址(若在用户态,则跳转到 uservec,若在内核态,则跳转到 kernelvec)
在 uservec 中,首先使用 csrw 将 a0 寄存器和 sscratch 寄存器的值进行交换,使得 a0 中存的是 trapframe 的地址,接下来就可以使用 a0 来寻址 trapframe。然后将 32 个寄存器保存在 trapframe 中,将内核栈指针、内核 hartid、usertrap 地址加载到寄存器中,并且将页表切换到内核页表(修改 satp),然后跳转到 usertrap()。
在 usertrap() 中,首先判断是否是从用户态来的 Trap(判断 SPP 位),然后因为当前已经在内核态,如果再发生中断 (系统调用里可能会再次中断),则转入内核处理函数,所以要将 stvec 修改位内核处理函数。然后将用户的 pc 保存到 epc,判断中断原因,如果是系统调用则开启中断,进入 syscall()。
然后将会调用 usertrapret 返回用户态,关闭中断,将 stvec 复原到用户态的处理函数,还原,还原 pc,然后执行 userret。
userret 中将页表切换(修改 satp),将 32 个寄存器还原,然后 sret。
内核态发生 Trap
kernelvec 中将寄存器保存在栈中,然后使用 call kerneltrap 调用 kerneltrap(),调用完后回到 kerneltrap(),恢复寄存器的值。
在 kerneltrap() 中,先判断是否从内核态来的 Trap,然后检查是否关闭中断防止重入,然后判断中断类型进行操作。此函数执行完后会回到 kernelvec。
系统调用过程
进入中断,寄存器 a7 存入系统调用号,a0 存系统调用的返回值。syscall 通过一个映射表找到对应的 syscall。
1 | // kernel/syscall.c |
系统调用参数存在 a0、a1、a2、a3、a4、a5,使用 argraw() 函数进行获取。
1 | // kernel/syscall.c |
文件系统
文件系统结构
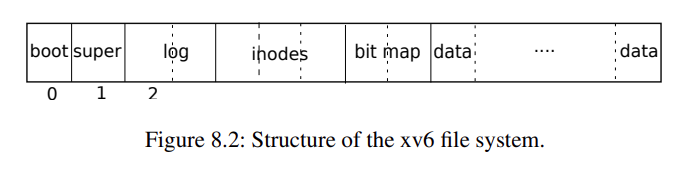
Block 0:包含 boot sectorBlock 1:称为 superblock (包含文件系统的信息,Block 数量、Inode 数量、在 log 内的 Block 数),被mkfs初始化Block 2开始:log blockinodesbitmap:记录哪个 data block 是在被使用的data:data block,数据块
inode
inode 有两层含义
- 硬盘上的 inode,包含文件的大小和数据块编号
- 内存中的 inode
硬盘 inode 在硬盘一个连续的区域 inode 块存储。每个 inode 是固定的 1024 字节。因此我们可以通过 inode 号找到指定编号的 inode。
1 | // kernel/fs.h |
所有内存中活动的 inode 都存进 itable 中。
1 | // kernel/fs.c |
只有有对该 inode 的引用才将其载入内存。
1 | // kernel/file.h |
ref 字段用来标识该 inode 被引用了几次。iget() 和 iput() 获取和释放 inode 的一个引用。对 inode 的引用来自 fd、当前工作目录以及 exec()。
iget() 和 iput() 在 kernel/fs.c 中。
nlink 字段用来标识有多少个目录项引用该文件。
ialloc() 分配一个 inode
inode 内容
开始 NDIRECT=12 个 block 直接放在 dinode 中的 addr[] 称为 direct blocks,之后 NINDIRECT 个 block 不放在 dinode 中而是放在 data block 中称为 indirect blocks,这些 block 的索引存在 addr[] 最后一个 block 中。
inode 结构
bmap() 找到 inode 中的第 n 个块,没有则分配。
readi() 和 writei() 分别可以读取和写 inode 的内容。
xv6 系统简单源码分析